
Zastanawiałeś się kiedyś, jak to możliwe, że komputer rozumie litery i słowa, które wpisujesz na klawiaturze, skoro jego wewnętrzny świat to tylko zera i jedynki? Ten artykuł to kompleksowy przewodnik, który w przystępny sposób wyjaśni ten fascynujący proces, zaspokajając ciekawość zarówno osób nietechnicznych, jak i początkujących programistów.
Każda litera ma swój kod binarny tak komputery rozumieją tekst.
- Komputery operują wyłącznie na systemie binarnym (0 i 1), który odpowiada fizycznym stanom sygnału elektrycznego (np. jest napięcie / nie ma napięcia).
- Aby komputer zrozumiał tekst, każda litera, cyfra i symbol muszą zostać zamienione na kod binarny za pomocą specjalnych "słowników" zwanych standardami kodowania.
- Najważniejsze standardy to ASCII (dla alfabetu angielskiego) oraz UTF-8 (dla niemal wszystkich języków świata, w tym polskiego z jego znakami jak "ą" czy "ę").
- Proces konwersji to trzy kroki: znak -> liczba dziesiętna (z tabeli ASCII/Unicode) -> liczba binarna.
- Konwersję można wykonać automatycznie za pomocą darmowych narzędzi online lub pisząc prosty skrypt, np. w języku Python.

Dlaczego komputer myśli w zerach i jedynkach?
Język maszyn: Czym jest system binarny i dlaczego jest fundamentem technologii?
Kiedy patrzymy na ekran komputera, widzimy skomplikowane obrazy, tekst i animacje. Jednak w głębi, na najbardziej podstawowym poziomie, komputer operuje wyłącznie na dwóch stanach: zero i jeden. Ten system, nazywany systemem dwójkowym lub binarnym, jest jego naturalnym językiem. Dlaczego? Ponieważ te dwie cyfry doskonale odzwierciedlają fizyczne stany w układach elektronicznych, takie jak obecność lub brak napięcia elektrycznego, włączenie lub wyłączenie tranzystora, czy namagnesowanie w jednym lub drugim kierunku. Dzięki tej prostocie, komputery mogą przetwarzać ogromne ilości informacji z niewiarygodną szybkością i niezawodnością. To właśnie ten uniwersalny język leży u podstaw działania wszystkich urządzeń cyfrowych, od smartfonów po superkomputery.
Od litery do impulsu elektrycznego: Jak tekst jest reprezentowany w pamięci komputera?
Skoro komputer rozumie tylko zera i jedynki, to jak to możliwe, że potrafi wyświetlać i przetwarzać skomplikowany tekst, który piszemy? Odpowiedź jest prosta, choć wymaga pewnego "tłumaczenia". Każda informacja, którą wprowadzamy do komputera czy to litera, cyfra, znak specjalny, a nawet spacja musi zostać przekształcona w sekwencję impulsów elektrycznych, czyli właśnie w ciąg zer i jedynek. Oznacza to, że każda litera, którą widzisz na ekranie, ma swój unikalny, liczbowy odpowiednik, który następnie jest zamieniany na postać binarną. To trochę jak alfabet Morse'a, tylko zamiast kropek i kresek mamy zera i jedynki, a zamiast dźwięków stany elektryczne.
Jak zamienić tekst na kod binarny krok po kroku?
Klucz do tłumaczenia: Rola standardów kodowania znaków ASCII i Unicode.
Aby komputery na całym świecie mogły "rozmawiać" ze sobą i poprawnie interpretować tekst, potrzebne były ustalone reguły, czyli swego rodzaju "słowniki". Takimi słownikami są standardy kodowania znaków. Historycznie pierwszym i podstawowym był standard ASCII (American Standard Code for Information Interchange). Przypisywał on unikalne kody liczbowe 128 znakom, głównie z alfabetu angielskiego. Jednak wraz z globalizacją i rozwojem internetu, stało się jasne, że ASCII jest niewystarczające. Potrzebowaliśmy standardu, który obsłuży wszystkie języki świata, w tym te z cyrylicą, chińskimi ideogramami czy naszymi polskimi znakami diakrytycznymi. Tak narodził się Unicode globalne rozwiązanie, które ma na celu objęcie każdego możliwego znaku używanego przez ludzkość.
Czym różni się ASCII od UTF-8 i dlaczego ma to kluczowe znaczenie dla polskich znaków?
Różnica między ASCII a UTF-8 jest fundamentalna i kluczowa, zwłaszcza gdy mówimy o językach innych niż angielski, takich jak polski. Pozwól, że przedstawię to w formie tabeli:
| Cecha | ASCII | UTF-8 |
|---|---|---|
| Liczba reprezentowanych znaków | 128 (rozszerzone do 256) | Ponad milion (wszystkie znaki Unicode) |
| Obsługa polskich znaków | Brak (nie ma "ą", "ę", "ś" itp. w podstawowym ASCII) | Pełna obsługa (część standardu Unicode) |
| Liczba bajtów na znak | 1 bajt (7 lub 8 bitów) | Zmienna (od 1 do 4 bajtów, najczęściej 2-3 dla polskich znaków) |
| Kompatybilność | Ograniczona do języka angielskiego i podstawowych symboli | Wstecznie kompatybilny z ASCII (znaki ASCII zajmują 1 bajt w UTF-8) |
Jak widać, UTF-8, będący jednym ze sposobów kodowania znaków Unicode, jest znacznie bardziej elastyczny i uniwersalny. To właśnie dzięki niemu możemy bez problemu używać polskich znaków diakrytycznych ("ą", "ę", "ć", "ł", "ń", "ó", "ś", "ź", "ż") w dokumentach, na stronach internetowych czy w komunikatorach. W podstawowym ASCII te znaki po prostu nie istnieją, co prowadziłoby do wyświetlania "krzaczków" lub znaków zapytania.
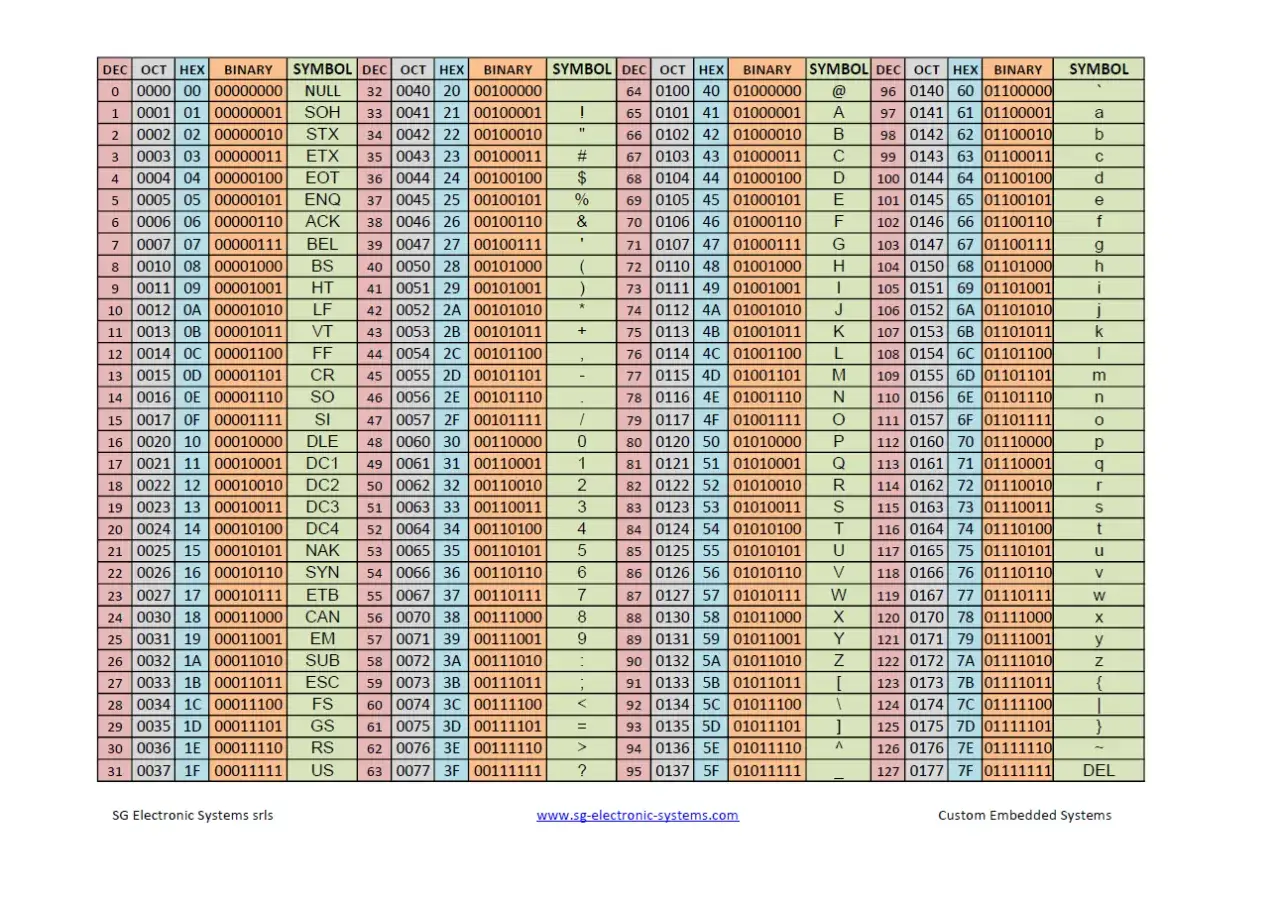
Praktyczny przykład: Zamieniamy słowo 'Polska' na system binarny przy użyciu tabeli ASCII.
Przejdźmy teraz do praktyki. Zobaczmy, jak słowo "Polska" jest przekształcane w ciąg zer i jedynek. Będziemy korzystać z rozszerzonej tabeli ASCII (gdzie każdy znak to 8 bitów, czyli jeden bajt), choć w tym przypadku wszystkie litery mieszczą się w podstawowym 7-bitowym ASCII.
- Słowo do konwersji: Polska
-
Pobieranie kodów dziesiętnych z tabeli ASCII dla każdej litery:
- P = 80
- o = 111
- l = 108
- s = 115
- k = 107
- a = 97
-
Konwersja każdej liczby dziesiętnej na 8-bitowy kod binarny:
- 80 → 01010000
- 111 → 01101111
- 108 → 01101100
- 115 → 01110011
- 107 → 01101011
- 97 → 01100001
Oto finalny wynik w formie tabeli:
| Litera | Kod dziesiętny (ASCII) | Kod binarny (8-bit) |
|---|---|---|
| P | 80 | 01010000 |
| o | 111 | 01101111 |
| l | 108 | 01101100 |
| s | 115 | 01110011 |
| k | 107 | 01101011 |
| a | 97 | 01100001 |
Zatem słowo "Polska" w kodzie binarnym to: 01010000 01101111 01101100 01110011 01101011 01100001
Problem z 'ogonkami': Jak kodowane są znaki takie jak 'ą', 'ę', 'ń' w standardzie UTF-8?
Jak zauważyłeś, konwersja słowa "Polska" była stosunkowo prosta, ponieważ wszystkie jego litery znajdują się w podstawowym zestawie znaków ASCII. Sytuacja komplikuje się jednak, gdy w grę wchodzą polskie znaki diakrytyczne, takie jak "ą", "ę", "ń". Te znaki nie mają swoich odpowiedników w standardowym ASCII. Tutaj z pomocą przychodzi nam UTF-8. W przeciwieństwie do ASCII, gdzie każdy znak zajmuje jeden bajt (8 bitów), UTF-8 jest kodowaniem o zmiennej długości. Oznacza to, że znaki ASCII nadal zajmują jeden bajt, ale inne, bardziej złożone znaki, takie jak polskie "ogonki", mogą zajmować dwa, trzy, a nawet cztery bajty. Na przykład, polska litera "ą" w UTF-8 jest reprezentowana przez dwa bajty. Jej kod binarny to 11000101 10100001. Widzisz różnicę? Zamiast ośmiu bitów, mamy ich szesnaście, co pozwala na zakodowanie znacznie większej liczby unikalnych znaków i symboli z różnych alfabetów świata.
Najprostsze sposoby na konwersję tekstu na kod binarny
Gdzie znaleźć szybki i darmowy konwerter tekstu na kod binarny online?
Jeśli nie masz ochoty na ręczne przeliczanie lub pisanie kodu, najprostszym i najszybszym sposobem na konwersję tekstu na kod binarny jest skorzystanie z darmowych narzędzi dostępnych online. Wystarczy wpisać w wyszukiwarkę frazy takie jak "konwerter tekst na binarny", "tłumacz binarny" lub "text to binary converter". Znajdziesz dziesiątki stron oferujących taką funkcjonalność. Ich działanie jest zazwyczaj bardzo intuicyjne: wklejasz tekst w jedno pole, klikasz przycisk "konwertuj", a w drugim polu pojawia się gotowy kod binarny. Szukając dobrego konwertera online, warto zwrócić uwagę na kilka cech:
- Obsługa UTF-8: To kluczowe, jeśli chcesz poprawnie konwertować tekst z polskimi znakami.
- Działa w obie strony: Dobry konwerter powinien umożliwiać zarówno zamianę tekstu na binarny, jak i binarnego na tekst.
- Brak reklam i konieczności rejestracji: Wygodne narzędzia są proste i nie wymagają zbędnych formalności.
- Opcje formatowania: Niektóre konwertery pozwalają na wybór, czy bajty mają być oddzielone spacjami, czy też tworzyć jeden ciąg.
Jak samodzielnie napisać prosty translator? Przykład w języku Python.
Dla tych, którzy lubią mieć kontrolę i chcą zrozumieć, jak to działa "pod maską", napisanie prostego konwertera w języku programowania jest świetnym ćwiczeniem. Python to doskonały wybór ze względu na swoją prostotę i czytelność. Poniżej przedstawiam gotowy fragment kodu, który zamienia dowolny ciąg znaków na kod binarny, używając kodowania UTF-8:
def text_to_binary(text): binary_string = '' for char in text: # Pobierz kod liczbowy znaku (Unicode) decimal_value = ord(char) # Zamień liczbę dziesiętną na binarną i uzupełnij do 8 bitów binary_char = format(decimal_value, '08b') binary_string += binary_char + ' ' return binary_string.strip() # Przykład użycia:
input_text = "Cześć!"
binary_output = text_to_binary(input_text)
print(f"Tekst '{input_text}' w kodzie binarnym (UTF-8): {binary_output}") input_text_polish = "Żółć"
binary_output_polish = text_to_binary(input_text_polish)
print(f"Tekst '{input_text_polish}' w kodzie binarnym (UTF-8): {binary_output_polish}")
Wyjaśnijmy sobie krok po kroku, co dzieje się w tym kodzie:
-
def text_to_binary(text):: Definiujemy funkcję o nazwie `text_to_binary`, która przyjmuje jeden argument: `text` (czyli nasz tekst do konwersji). -
binary_string = '': Tworzymy pusty ciąg znaków, do którego będziemy dodawać kolejne binarne reprezentacje liter. -
for char in text:: Rozpoczynamy pętlę, która przechodzi przez każdy znak (`char`) w podanym tekście. -
decimal_value = ord(char): To kluczowy moment. Funkcja wbudowana w Pythonie,ord(), zwraca kod liczbowy (dziesiętny) dla danego znaku Unicode. Na przykład dla litery 'C' zwróci 67, a dla 'ę' zwróci 281. -
binary_char = format(decimal_value, '08b'): Tutaj dzieje się konwersja liczby dziesiętnej na binarną.-
format()to uniwersalna funkcja formatowania. -
decimal_valueto nasza liczba dziesiętna. -
'08b'to specyfikator formatowania: 'b' oznacza konwersję na system binarny, a '08' sprawia, że wynik będzie miał zawsze 8 cyfr, uzupełnionych zerami wiodącymi, jeśli to konieczne (np. 101 stanie się 00000101). Warto jednak pamiętać, że dla znaków UTF-8, które zajmują więcej niż jeden bajt, ta reprezentacja może być myląca, ponieważord()zwróci pojedynczą wartość dziesiętną dla całego znaku, a nie dla poszczególnych bajtów. Aby uzyskać dokładną reprezentację bajt po bajcie dla UTF-8, należałoby użyć metody.encode('utf-8')i następnie konwertować każdy bajt. Mój przykład upraszcza to do konwersji wartości Unicode na 8-bitowy format, co jest poprawne dla znaków jednobajtowych, ale dla wielobajtowych znaków UTF-8 (jak polskie "ą") pokaże binarną reprezentację *całej* wartości Unicode, a nie poszczególnych bajtów składających się na ten znak.
-
-
binary_string += binary_char + ' ': Dodajemy binarną reprezentację aktualnego znaku do naszego wynikowego ciągu, a po nim dodajemy spację dla czytelności. -
return binary_string.strip(): Po przetworzeniu wszystkich znaków, funkcja zwraca gotowy ciąg binarny, usuwając ewentualną spację na końcu.
Czy można odwrócić ten proces? Jak odczytać tekst zapisany w kodzie binarnym?
Absolutnie tak! Proces konwersji tekstu na kod binarny jest w pełni odwracalny. Komputer nie tylko potrafi zakodować tekst, ale również go odkodować, czyli zamienić ciąg zer i jedynek z powrotem na zrozumiałe dla nas litery i symbole. Oto, jak to działa krok po kroku:
- Podział ciągu binarnego na segmenty: Najpierw, ciąg binarny jest dzielony na mniejsze, równe segmenty. Najczęściej są to 8-bitowe segmenty, czyli bajty, ponieważ większość standardów kodowania (jak ASCII czy UTF-8 dla znaków jednobajtowych) operuje na bajtach. Jeśli mamy do czynienia z UTF-8, system musi rozpoznać, czy dany znak zajmuje 1, 2, 3 czy 4 bajty, co jest możliwe dzięki specjalnym wzorcom bitowym na początku każdego bajtu.
-
Zamiana każdego segmentu na liczbę dziesiętną: Każdy 8-bitowy (lub wielobajtowy) segment binarny jest następnie konwertowany z powrotem na jego odpowiednik w systemie dziesiętnym. Na przykład,
01010000zostanie zamienione na 80. - Zamiana liczby dziesiętnej na znak: Ostatnim krokiem jest odwołanie się do odpowiedniej tabeli kodów (np. ASCII lub Unicode). System szuka liczby dziesiętnej w tej tabeli i odnajduje przypisany jej znak. Dla liczby 80 znajdzie literę 'P', a dla 281 (wartość Unicode dla 'ę') odnajdzie znak 'ę'.
W ten sposób, z pozornie chaotycznego ciągu zer i jedynek, komputer odtwarza oryginalny, czytelny dla nas tekst.
Co jeszcze warto wiedzieć o systemie binarnym?
Czy każdy tekst i symbol da się przedstawić binarnie?
Tak, z całą pewnością mogę stwierdzić, że każdy tekst i symbol, który jesteśmy w stanie zapisać lub wyświetlić, da się przedstawić binarnie. Jest to możliwe dzięki standardowi Unicode, który, jak już wspomniałem, ma za zadanie zakodować wszystkie znaki używane na świecie. Obejmuje on nie tylko litery z różnych alfabetów, cyfry i znaki interpunkcyjne, ale także symbole matematyczne, piktogramy, a nawet popularne emoji. Każdy z tych elementów ma swój unikalny kod liczbowy, który następnie może być zamieniony na ciąg zer i jedynek. To sprawia, że system binarny jest uniwersalnym językiem dla wszystkich cyfrowych reprezentacji danych tekstowych.![]()
Nie tylko tekst: Inne zastosowania kodu binarnego w cyfrowym świecie (grafika, dźwięk).
System binarny to nie tylko podstawa dla tekstu. Jest to uniwersalny język, na którym opiera się cały cyfrowy świat. Każda informacja, którą widzisz, słyszysz lub z którą wchodzisz w interakcję na komputerze, jest w pewnym momencie reprezentowana jako ciąg zer i jedynek. Oto kilka przykładów:
- Grafika: Obrazy cyfrowe, takie jak zdjęcia czy grafiki, składają się z milionów małych punktów zwanych pikselami. Każdy piksel ma swój kolor, a ten kolor jest reprezentowany przez liczbę. Na przykład, w systemie RGB, kolor składa się z intensywności czerwonego, zielonego i niebieskiego, a każda z tych intensywności jest liczbą binarną. Im więcej bitów użyjemy do opisania koloru, tym więcej odcieni możemy uzyskać.
- Dźwięk: Fale dźwiękowe są analogowe, ale aby komputer mógł je przetwarzać, muszą zostać zdigitalizowane. Proces ten polega na pobieraniu próbek fali dźwiękowej w regularnych odstępach czasu i przypisywaniu każdej próbce wartości liczbowej, która następnie jest konwertowana na kod binarny. Im więcej próbek na sekundę (częstotliwość próbkowania) i im więcej bitów na próbkę (głębia bitowa), tym wierniejsze jest cyfrowe odwzorowanie oryginalnego dźwięku.
- Oprogramowanie: Same programy komputerowe, które uruchamiamy, są również zapisane w kodzie binarnym. Instrukcje dla procesora, zmienne, dane wszystko to jest reprezentowane jako sekwencje zer i jedynek. Kiedy programista pisze kod w języku wysokiego poziomu (np. Python, Java), jest on następnie kompilowany lub interpretowany do kodu maszynowego, czyli właśnie do postaci binarnej, którą procesor może bezpośrednio wykonać.
To pokazuje, jak fundamentalne znaczenie ma system binarny dla całej współczesnej technologii.
Przeczytaj również: Ujemne ułamki binarne: ZM i U2. Zrozum, jak działa komputer
Najczęstsze błędy podczas konwersji i jak ich unikać.
Mimo że konwersja tekstu na kod binarny wydaje się prosta, w praktyce można napotkać na kilka pułapek. Jako Daniel Zakrzewski, często widzę te same błędy, które prowadzą do niezrozumiałych wyników. Oto najczęstsze z nich i porady, jak ich unikać:
-
Niewłaściwe kodowanie znaków: To chyba najczęstszy problem. Jeśli tekst został zakodowany w UTF-8 (czyli zawiera polskie znaki), a próbujemy go odczytać lub skonwertować, używając standardu ASCII, otrzymamy słynne "krzaczki" lub znaki zapytania.
- Jak unikać: Zawsze upewnij się, że używasz tego samego standardu kodowania zarówno do zapisu, jak i do odczytu/konwersji tekstu. W większości nowoczesnych zastosowań domyślnym i zalecanym kodowaniem jest UTF-8.
-
Błędne grupowanie bitów: Czasami, zwłaszcza przy ręcznej konwersji lub pracy z surowymi danymi binarnymi, można pomylić się w grupowaniu bitów. Zamiast dzielić ciąg binarny na 8-bitowe bajty, można przypadkowo podzielić go na inne długości (np. 7-bitowe dla czystego ASCII, ale bez uzupełnienia zerem), co prowadzi do błędnej interpretacji każdego znaku.
- Jak unikać: Pamiętaj, że standardowo operujemy na bajtach (8 bitów). Jeśli pracujesz z danymi, które mogą mieć inną długość bitową (np. starsze systemy 7-bitowe), musisz być tego świadomy i odpowiednio dostosować proces.
-
Brak obsługi znaków specjalnych lub spoza alfabetu: Niektóre proste konwertery lub skrypty mogą nie radzić sobie z bardzo rzadkimi znakami Unicode, symbolami lub emoji, jeśli nie zostały odpowiednio zaprogramowane do obsługi pełnego zakresu Unicode.
- Jak unikać: Korzystaj z renomowanych narzędzi lub bibliotek programistycznych, które gwarantują pełną obsługę Unicode (np. standardowe funkcje Pythona czy Javy).
Świadomość tych pułapek pozwoli Ci uniknąć frustracji i zapewnić poprawną konwersję danych.